A feladatok egymásra épülnek ezért érdemes ezeket a megadásuk sorrendjében megoldani, de legalább megérteni az aktuális feladatot megelőző feladatokat! A függvények definíciójában lehet, sőt javasolt is alkalmazni a korábban definiált függvényeket (függetlenül attól, hogy sikerült-e azokat megadni).
Tekintve, hogy a tesztesetek, bár odafigyelés mellett íródnak, nem fedik le minden esetben a függvény teljes működését, határozottan javasolt még külön próbálgatni a megoldásokat beadás előtt, vagy megkérdezni a felügyelőket!
Részpontszámokat csak az elégséges szint elérése után lehet kapni!
A feladat összefoglaló leírása
A Huffman-kódolás karakterek (jelek, betűk, számjegyek) olyan kódolását jelenti, ahol az egyes karakterekhez rendelt kódok nem azonos hosszúságúak (különböző számú bitből állnak), így a belőlük alkotott szöveg hosszában rövidíthetővé válik. Ez a karakterek gyakoriságának figyelembe vételével történik. Maga a kódolás egy mohó stratégián alapszik, és az adattömörítésben igen hatékonyan használható. A kapcsolódó algoritmust David A. Huffman (1925–1999) írta le először egy mesteri vizsgadolgozatban, és 1952-ben publikálta.
A kódolás során egy speciális adatszerkezetet (lényegében egy bináris fát, amely most egyszerűen csak listaként ábrázolunk) építünk fel lépésről-lépésre, a következő módon:
Kiválasztjuk a lista két legkisebb gyakoriságú elemét, amely egy háromcsúcsú bináris fa két levele (olyan csúcs, amelynek nincs gyereke) lesz (amelyeket a gyakorisággal címkézzük meg), majd ezekhez hozzárendelünk egy gyökeret, amelyet a két gyakoriság összegével címkézünk meg.
Ezután a két vizsgált elemet kitöröljük a listából, és azok összegét beszúrjuk az érték szerinti megfelelő helyre, hogy a lista rendezettsége megmaradjon.
Ezután folytatjuk a műveletet az 1. lépésnél mindaddig, amíg van elem a listában.
Az így felépített adatszerkezetben a levelek az eredeti karaktereknek (illetve azok gyakoriságának) felelnek meg.
Az eredményül kapott fában, minden csúcs esetében címkézzük meg 0-val a belőle kiinduló bal oldali élt, 1-gyel pedig a jobb oldalit.
A gyökértől egy adott levélig egyetlen út halad. Ezen út éleihez rendelt 0 és 1 címkéket sorrendben összeolvasva, megkapjuk a levélhez rendelt karakter kódját. Látható, hogy a gyakoribb karakterek kódja rövidebb, míg a kevésbé gyakoribbaké hosszabb lesz.
Megjegyzés: Attól függően, hogy a bináris fa felépítésében egy adott lépésben melyik elem kerül balra és melyik jobbra, különböző eredményt kaphatunk, de ez nem befolyásolja a kapott kód hatékonyságát, illetve a megoldás helyességét.
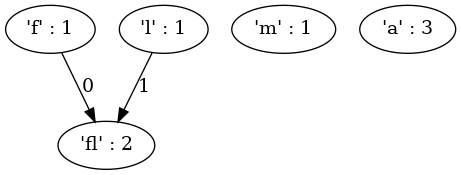
Példa (“almafa” szöveg kódfája)
Kezdőállapot (4 csúcs a karakterekkel, illetve gyakoriságukkal megcímkézve)
lépés után (‘f’ : 1 és ‘l’ : 1 összevonása — létrejön ‘fl’ : 2 csúcs)
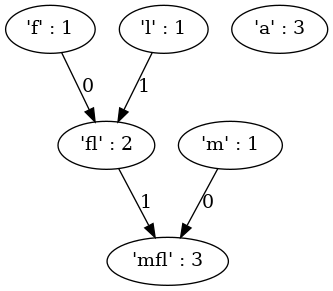
lépés után (‘m’ : 1 és ‘fl’ : 2 összevonása — létrejön ‘mfl’ : 3 csúcs)
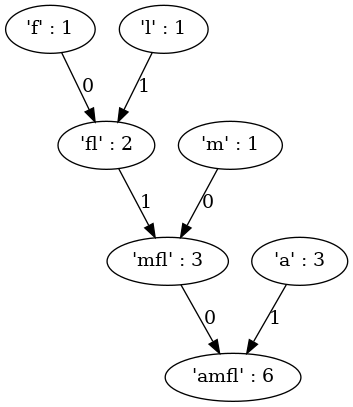
lépés után (‘mfl’ : 3 és ‘a’ : 3 összevonása — létrejön ‘amfl’ : 6 csúcs — elkészült a fa)
A kódtábla: a csúcstól a levelek felé az éleket összeolvasva megkapjuk: a -> 1, m -> 00, f -> 010, l -> 011
Az ‘almafa’ szöveg kódja: 10110010101
Betűgyakoriságok (1 pont)
A gyakoriságok ábrázolásához használjuk a következő típusokat:
Számoljuk meg a paraméterként kapott szövegben az egyes betűk előfordulásainak a számát! Az eredmény listában az egyes karaktereket mint egy hosszúságú sztringeket ábrázoljuk a későbbi, egyszerűbb felhasználhatóság érdekében.
Megjegyzés: Az eredményben a rendezett párok az első elemük szerint rendezettek.
A gráf csúcsait (Node) rendezett párokkal adjuk meg. A rendezett pár első komponense a csúcs azonosítója (Id), a második pedig a betű és annak előfordulási gyakorisága (LetterSum). A gráf élei irányítottak (Edge), az éleket ábrázoló hármas első két komponense a kiinduló és a célcsúcs azonosítója (Id), a harmadik komponens pedig az él címkéje.
Állítsunk elő az algoritmus kezdőállapotát (State), melyet az alábbi rendezett hármasként tudunk felírni:
A rendezett hármas balról jobbra a következő komponensekből épül fel:
[Node] a feldolgozandó csúcsok listája: a csúcsokat 1-től indexeljük, ahol a sorrend fontos, ez gyakoriság alapján növekvő (egyenlő gyakoriság esetén a karakterek alapján rendezzük, szintén növekvő),
[Edge] az éllista, mely kezdetben üres,
[Node] a már feldolgozott csúcsok listája, mely kezdetben szintén üres.
A startState a betű-gyakoriság párokat egy rendezetlen listában kapja meg. Ezt rendezni kell a gyakoriság alapján a sorszámozás előtt.
A gráf csúcsait 1-től kezdve sorszámoztuk a kezdőállapot elkészítésekor. A későbbiekben, ha újabb csúcsot készítünk, akkor ennek szüksége lesz egy olyan azonosítóra, amely még nem szerepel a State-ben. A nextId függvény keresse meg a használt azonosítók közül a legnagyobbat és adjon vissza ennél eggyel nagyobb értéket!
Megjegyzés: Feltehetjük, hogy az állapotban mindig van legalább egy csúcs.
Készítsük el a createNode függvényt, mely létrehoz egy új csúcsot! A függvény az új csúcs azonosítóját és a gráfbeli gyerekeit, x és y, várja paraméterül. Az új csúcs gyakorisága az x és y csúcsok gyakoriságának összege, a címkéje pedig az x és y csúcsok címkéje egymás után fűzve.
Illesszünk be egy új csúcsot a kapott Node listába úgy, hogy a lista (Frequency értéke alapján vett) rendezettsége megmaradjon! Azonos Frequency esetén az első lehetséges helyre történjen a beszúrás. Fontos, hogy a sorrendet megőrizzük!
Megjegyzés: A feladatban az azonosítók (Id) esetleges ütközésére, illetve azok folytonosságára nem kell figyelni!
Ha csak egyetlen csúcs van a feldolgozandók listájában, akkor azt helyezzük át a feldolgozott csúcsok listájába.
Ha van legalább két feldolgozatlan csúcs:
A feldolgozatlan csúcsok közül válasszuk ki a két legkisebb gyakoriságú csúcsot. Nevezzük x-nek a legkisebbet, y-nak a második legkisebbet. Ha több egyforma érték van, akkor azt választjuk, amelyik korábban szerepel a listában. Feltesszük, hogy a feldolgozatlan csúcsok rendezettek gyakoriságuk szerint.
Készítsünk egy új z csúcsot, melynek a gyakorisága az x, y csúcsok gyakoriságának összege, a címke mezőt pedig az előbbi x, y csúcsok címke mezőjének egymás után fűzésével kapjuk. A z csúcs azonosítóját generáljuk a nextId függvénnyel!
Az új csúcshoz kössük 1-1 irányított éllel az x, y csúcsokat (tehát az élek iránya: x -> z, y -> z). Az új élek Label mezőjének kitöltése: az x csúcsból induló élnél "0", míg az y-ból indulónál "1" legyen.
Tegyük át az x és y csúcsokat a feldolgozottak közé (tetszőleges helyre), a z csúcsot pedig a feldolgozatlanok közé. Ügyeljünk arra, hogy a z csúcs a gyakoriság alapján megfelelő helyre kerüljön!
Megjegyzés: Üres csúcslistára váltsunk ki hibát az error függvénnyel!
Ismételjük az előző függvényben megvalósított csúcsösszevonást egészen addig, amíg a State-ben a feldolgozásra váró csúcsok listája ki nem ürül! Az eredmény típusa legyen az alábbi:
Egy csúcs azonosítója és az éllista alapján döntsük el, hogy a csúcsnak van-e szülője, vagyis vezet-e ki irányított él a kapott Id-vel azonosított csúcsból!
Gyűjtsük össze a felépített adatszerkezetből egy csúcs kódját! Ehhez csak annyit kell tennünk, hogy a kapott csúcsból (pontosabban a kapott Id-hez tartozó csúcsból) elindulunk és követjük az irányított éleket. Ezek mindig a szülő csúcs felé vezetnek, amíg van ilyen. Menet közben pedig összegyűjtjük egy listában az összes érintett él Label értékét. A kódot megkapjuk az összegyűjtött címkéket fordított sorrendben összeolvasva.
A felépített adatszerkezetből állítsuk elő a teljes kódtáblát, melyben karakterekhez rendeljük a kódjukat! Szűrjük ki a kész állapot feldolgozott csúcsai közül azokat, melyek 1 karakterből álló szöveget tartalmaznak. Minden ilyen csúcs azonosítóját felhasználva a csúcsban tárolt egyetlen karakterhez tartozó kódot állítsuk elő a getCodeForOne függvénnyel!
Írjuk meg a findCode függvényt, mely ki tud keresni a kódtáblában egy adott karakterhez tartozó kódot! Feltesszük, hogy a kódtábla nem üres és mindig megtalálható benne a keresett karakter.
Írjuk meg a findChar függvényt, mely kikeresi a kódtáblában egy megadott kódhoz tartozó karaktert! Feltesszük, hogy a kódtábla nem üres és mindig megtalálható benne a keresett kód.
Dekódoljunk egy szöveget a megadott kódtábla alapján! Az eredeti szöveget karakterről-karakterre fejtjük vissza. Ehhez az alábbi lépések szükségesek:
Keressük meg a kódtáblában azt a kódot, amelyik prefixe a paraméterül kapott kódsorozatnak. Ehhez a prefixhez tartozó karakter lesz a dekódolt szöveg első karaktere, melyet a findChar függvénnyel deríthetünk ki.
Fejtsük vissza rekurzívan a maradék kódot. Az így visszafejtett szöveg elé fűzzük az előző pontban visszafejtett karaktert.
Megjegyzés: A dekódolás mindig egyértelmű, mert az előállított kódok nem prefixei egymásnak, így a dekódolandó szöveg mindig egyértelműen (mohó módon) felbontható a kódtábla alapján.