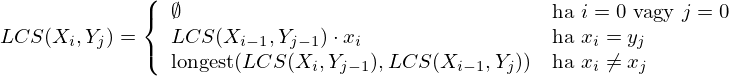Ebben a feladatban a diff(1) segédprogram működését fogjuk naiv módon modellezni, ennek a részleteit kell egyenként megvalósítani. Ezt a programot arra szokták használni, hogy két szöveges állomány tartalmát soronként összevessék és megmutassák, hol vannak a kettő között esetleges eltérések. Ilyenkor előfordulhat, hogy az egyik állományba a másikhoz képest újabb sorokat szúrtunk be vagy éppen távolítottunk el, de az is lehet, hogy a kettő nem különbözik semmiben sem egymástól.
A program, valamint a feladatban is szereplő függvények összefoglaló működéséhez tekintsünk két szöveges állomány, az f1.txt:
HA FÉRFI VAGY, LÉGY FÉRFI...
Ha férfi vagy, légy férfi,
S ne hitvány gyönge báb,
Mit kény és kedv szerint lök
A sors idébb-odább.
Félénk eb a sors, csak csahol;
A bátraktól szalad,
Kik szembeszállanak vele...
Azért ne hagyd magad!
Ha férfi vagy, légy férfi,
S ne szád hirdesse ezt,
Minden Demosthenesnél
Szebben beszél a tett.
Építs vagy ronts, mint a vihar,
S hallgass, ha műved kész,
Mint a vihar, ha megtevé
Munkáját, elenyész.
és az f2.txt tartalmát:
Ha férfi vagy, légy férfi,
Legyen elved, hited,
És ezt kimondd, ha mindjárt
Véreddel fizeted.
Százszorta inkább éltedet
Tagadd meg, mint magad;
Hadd vesszen el az élet, ha
A becsület marad.
Ha férfi vagy, légy férfi,
Függetlenségedet
A nagyvilág kincséért
Árúba ne ereszd.
Vesd meg, kik egy jobb falatért
Eladják magokat.
„Koldúsbot és függetlenség!”
Ez légyen jelszavad.
Ekkor a kettő közti eltéréseket az ún. “unified diff” formátumban lehet meghatározni. Ennek az a lényege, hogy kisebb csoportokba szervezve megkeressük a szövegekben az eltérő részleteket, majd '-' jelekkel megadjuk, hogy mi szerepelt azon a helyen az első, '+' jelekkel pedig azt, hogy mi szerepelt a második állományban. Az előbbi szövegek esetében ez így lehet megnézni:
$ diff -U 0 f1.txt f2.txt
--- f1.txt
+++ f2.txt
@@ -1,2 +0,0 @@
-HA FÉRFI VAGY, LÉGY FÉRFI...
-
@@ -4,7 +2,7 @@
-S ne hitvány gyönge báb,
-Mit kény és kedv szerint lök
-A sors idébb-odább.
-Félénk eb a sors, csak csahol;
-A bátraktól szalad,
-Kik szembeszállanak vele...
-Azért ne hagyd magad!
+Legyen elved, hited,
+És ezt kimondd, ha mindjárt
+Véreddel fizeted.
+Százszorta inkább éltedet
+Tagadd meg, mint magad;
+Hadd vesszen el az élet, ha
+A becsület marad.
@@ -13,7 +11,7 @@
-S ne szád hirdesse ezt,
-Minden Demosthenesnél
-Szebben beszél a tett.
-Építs vagy ronts, mint a vihar,
-S hallgass, ha műved kész,
-Mint a vihar, ha megtevé
-Munkáját, elenyész.
+Függetlenségedet
+A nagyvilág kincséért
+Árúba ne ereszd.
+Vesd meg, kik egy jobb falatért
+Eladják magokat.
+„Koldúsbot és függetlenség!”
+Ez légyen jelszavad.
A program kimenetének elején "---" után jelenik meg az első, "+++" után a második állomány neve. Ezt követően csoportokba szedetten felsoroljuk az állományok eltéréseit úgy, hogy azok pozícióját "@@" jelek között bevezetésképpen megadjuk. Így például a második ilyen csoport a "-4,7 +2,7" koordinátákkal kezdődik. Ez arra utal, hogy ott az eltérések mind az egyik szövegben a negyedik, a másikban a második sortól kezdődnek és hét soron keresztül tartanak.
Az így előállítható kimeneteket el lehet menteni, ezeket szokták .diff vagy .patch kiterjesztésű állományoknak hívni. Segítségével ugyanis egy másik program, a patch(1) képes az eredeti, jelen esetünkben az f1.txt, állományból létrehozni a másik, itt az f2.txt, állományt. Ha elég kicsik az eltérések, akkor ezzel hatékonyabban el lehet tárolni (és onnan visszaállítani) egy állomány különböző változatait, ezért is szokták ezt gyakran verziókövetésre is használni, mint amit a Subversion, Mercurial vagy a Git valósítanak meg.
Megjegyezzük, hogy a diff(1) hagyományos kimenetétől eltérően a feladat egyszerűsítése kedvéért most nem tesszük hozzá az csoportokba szedett eltérésekhez a környezetüket (ennek a neve “context”), ezért adtuk meg az -U 0 kapcsolót az ilyenkor egyébként szokásos -u helyett. Továbbá nagyobb szövegek esetében az itt felvázolt megoldás nem lesz hatékony.
A feladatok egymásra épülnek, ezért érdemes ezeket a megadásuk sorrendjében megoldani, de legalább megérteni az aktuális feladatot megelőző feladatokat! A függvények definíciójában lehet, sőt javasolt is alkalmazni a korábban definiált függvényeket (függetlenül attól, hogy sikerült-e azokat megadni). Beadni viszont a teljes megoldást kell, vagyis az összes függvény definícióját egyszerre!
Tekintve, hogy a tesztesetek, bár odafigyelés mellett íródnak, nem fedik le minden esetben a függvény teljes működését, határozottan javasolt még külön próbálgatni a megoldásokat beadás előtt!
Leghosszabb közös részsorozat
A diff(1) működésének alapja a két szöveg sorainak leghosszabb közös részsorozatának meghatározása. Ezeket általánosságban két lista mint sorozatok összehasonlítására vezethetjük vissza, ahol, mivel csak közös részsorozatokat keresünk, csak annyit várunk el, hogy annak elemei az egyes listákban egymás után forduljanak elő, de nem feltétlenül követik egymást közvetlenül.
Ennek kiszámításának módja megadható egyetlen rekurzív matematikai függvénnyel:
ahol Xi az első sorozat i hosszúságú kezdőszelete, xi az első sorozat i. eleme, Yj a második sorozat j hosszúságú kezdőszelete, yj a második sorozat j. eleme, valamint a longest két sorozat közül a hosszabbat adja vissza, a ⋅ művelet pedig a konkatenáció.
Példa
Tekintsük át a működést egy példán keresztül! Számítsuk ki a függvény alkalmazásával a "GAC" és "AGCAT" karaktersorozatok legnagyobb közös részsorozatát!
Mivel a két sorozat teljes hosszára vonatkozóan akarjuk ezt kiszámítani, az Xi és Yj kezdeti értékei maguk a karaktersorozatok lesznek, "GAC" és "AGCAT". (Egy n hosszúságú sorozat n hosszúságú kezdőszelete maga a sorozat.) Így az első sorozat i. eleme, az xi a 'C', a második sorozat j. eleme, az yj a 'T' lesz. Mivel ezek nem egyenlőek, a harmadik esetet választjuk.
Látszik, hogy a folytatáshoz az LCS("GAC","AGCA") és az LCS("GA","AGCAT") értékeit kell kiszámítani, és így tovább. Az alszámítások között az is látszik majd, hogy az LCS("GAC","AGC") esetében a második esetet választjuk, mivel az utolsó karakterek megegyeznek:
LCS("GA","A") = LCS("G", "") * 'A'
Itt a megkapott értékeket bővítjük a konkatenáció műveletével ('*'). Ha pedig valamelyik karaktersorozat üres lesz, akkor a válasz az első eset értelmében automatikusan üres:
A leghosszabb közös részsorozatok hosszainak táblázatos alakja
Szeretnénk a leghosszabb részsorozatok hosszait táblázatos alakban, egy mátrix formájában megadni, amelyhez most nem listák listáját használjuk fel. Helyette készítsünk egy olyan függvényt, amely megkapja paraméterül a két összehasonlítandó sorozatot, valamint azok kezdőszeleteinek hosszát és abból kiszámítja azokra a leghosszabb közös részsorozat hosszát!
Ne feledjük, hogy a kezdőszeletek hossza 0 és az adott sorozat hossza között változhat. Amennyiben ez nem teljesül, akkor az error függvény felhasználásával jelezzünk hibát! A hibaüzenetben adjuk meg a hibás indexeket (a példákban látható módon). Itt használhatjuk a show függvényt, amellyel számokat tudunk szöveggé alakítani.
egynek, ha az eredetihez képest beszúrunk, valamint
kettőnek, ha az eredetihez képest törlünk egy elemet a sorozatból.
A pár második eleme azt a konkrét elemet tartalmazza, amelyre a művelet vonatkozik. Mivel általánosan fogalmazzuk meg, ezért annak a típusát sem rögzítjük.
Hogy könnyebben tudjunk dolgozni ezzel az absztrakcióval, készítünk három segédfüggvényt, amelyek a paraméterül kapott értéket segítenek a megfelelő számhoz társítani.
Írjunk egy olyan függvényt, amely az előbbi módon létrehozott eltéréseket képes értelmezni! Ez a függvény kap három függvényt, amelyek rendre azt adják meg, hogy mit kell tennünk a pár második elemével attól függően, hogy milyen változtatást ír le. Ennek felhasználásával a Difference értékeket egy másik típusú értékre tudjuk leképezni.
Adjunk meg egy olyan függvényt, amely meghatározza egyenként, hogy pontosan milyen változások jelennek meg a paramétereként átadott két sorozat között!
Ennek alapja az a mátrix, amelyik a részsorozatok kezdőszeletei esetén adja meg leghosszabb közös részsorozat hosszát. Ezt most legyen C, és a Ci, j jelölje a i és j koordinátákhoz kiszámított értéket. Továbbá xi megadja az első sorozat i., yj pedig a második sorozat j. elemét.
Ezek felhasználásával a következő algoritmus alapján tudjuk összegyűjteni a változásokat:
Legyen i az első sorozat, j a második sorozat hossza.
Ha i > 0 ∧ j > 0 ∧ xi = yj, akkor adjuk hozzá azonosként (a same függvénnyel) az xi-t az eggyel rövidebb kezdőszeleteken kiszámított eltérésekhez.
Ha (j > 0 ∧ i = 0) ∨ (i > 0 ∧ j > 0 ∧ Ci, j − 1 ≥ Ci − 1, j), akkor adjuk hozzá (az add függvénnyel) beszúrásként az yj-t az első sorozat változatlan, és második sorozat eggyel rövidebb hosszúságú részsorozatán kiszámított eltérésekhez.
Ha (i > 0 ∧ j = 0) ∨ (i > 0 ∧ j > 0 ∧ Ci, j − 1 < Ci − 1, j), akkor adjuk hozzá (a del függvénnyel) törlésként az xi-t az első sorozat eggyel rövidebb, a második sorozat változatlan hosszúságú részsorozatán kiszámított eltérésekhez.
Készítsünk egy olyan függvényt, amely a változtatások sorozatát felbontja olyan részekre, amelyekben vagy csak a same függvénnyel létrehozott, vagy minden más (add és del függvényekkel létrehozott) változtatások szerepelnek!
Segítség: Használjuk a Data.List.groupBy függvényt!
Készítsünk egy olyan függvényt, amely változtatások egy olyan sorozatát kapja meg, amely csak és kizárólag az add vagy a del függvényekkel létrehozott értékeket tartalmazhat, és ennek elemeit szétválogatja aszerint, hogy pontosan melyikükkel hoztuk létre azokat!
Eredményként a függvény két listát (vagyis listák rendezett párját) adjon vissza, ahol az elsőben az add függvénnyel létrehozott, a másodikban pedig a del függvénnyel létrehozott elemek szerepelnek. Ha a függvény valamiért mégis olyan elemet találni a bemeneti listában, amely nem ezekbe a kategóriákba tartozik, álljon meg a példákban látható hibaüzenettel!
Írjunk egy olyan függvényt, amely elhagyja az azonos részeket és a tényleges eltérésekből összefüggő bejegyzéseket készít! Az egyes bejegyzéseket ezzel a szinonimával írjuk le:
Ez tehát egy rendezett hármas. Ennek első tagja egy nemnegatív egész szám, amely megadja, hogy az adott összefüggő eltéréssorozat az első sorozatban melyik pozíciótól kezdődik. Hasonlóan, a második tag is egy nemnegatív egész szám, és ez azt adja meg, hogy az eltéréssorzat a második sorozatban melyik pozíciótól kezdődik. Végül felsoroljuk magukat a változásokat, továbbra is feltéve, hogy bennük a same függvénnyel létrehozottak nem szerepelhetnek.
Például a következő bejegyzés egy olyan eltéréssorozatot ábrázol, amelyik az első sorozatban a 4, a második sorozatban a 2 pozíciótól indul, egy törlés és három beszúrás szerepel benne:
A pozíciók számozását kezdjük nullától és mindig annyival növeljük az első értéket, amennyi törlés, illetve annyival növeljük a második értéket, amennyi beszúrás volt az eltéréssorozatban. Továbbá minden olyan esetben megnöveljük eggyel ezeket az előbbiek szerint kiszámított értékükön felül, amikor vannak törlések vagy beszúrások az adott eltéréssorozatban.
Például tekintsük azt az esetet, amikor a következő listát kapjuk:
Ekkor mind a két sorozatból a nulladik pozícióról indulunk, viszont csak az elsőnél fogjuk eggyel növelni ezt az értéket, mivel csak törlések voltak a eltérések között. Ezért erre ez a válasz:
Hasonlóan működik a függvény csak beszúrások esetében is (ilyenkor csak a másik pozíció növekszik eggyel), illetve, ha mind a két fajta változás volt, akkor értelemszerűen mind a két pozíció növekszik eggyel. Például:
akkor ezt kapnánk (mivel az előző eltéréssorozatban két add és két del volt, így az előző pozíciókat egyaránt kettővel növeljük, illetve ismét mind a két fajta változás volt, mindegyik pozíciót növeljük eggyel):
Arra ügyeljünk a megvalósítás során, hogy az átugrott, a két sorozatban azonos részek hosszát is számoljuk bele a bejegyzések kezdőpozícióinak meghatározásakor!
Az összefüggő eltérések megjelenítése szövegek esetében
Valósítsuk meg azt a függvényt, amely segítségével azokban az esetekben, amikor az összehasonlítandó sorozatok szövegeket, vagyis String típusú értékeket, tartalmaznak, hozzá tudjuk rendelni annak szöveges változatát! Ez a korábban definiált Hunk típus értelmezése, ahol a benne leírt változtatások mögött String értékek vannak.
A a bejegyzés kezdőpozíciója az első sorozatban (vagyis a Hunk rendezett hármasának első eleme),
n a bejegyzés törlést végző műveleteinek száma (vagyis a Hunk eltárolt eltéréssorozatából azon változtatások száma, amelyeket a del függvénnyel hoztunk létre), amely csak akkor jelenik meg, ha nem egy,
B a bejegyzés kezdőpozíciója a második sorozatban (vagyis a Hunk rendezett hármasának második eleme),
m a bejegyzés beszúrást végző műveleteinek száma (vagyis a Hunk eltárolt eltéréssorozatából azon változtatások száma, amelyeket az add függvénnyel hoztunk létre), amely csak akkor jelenik meg, ha nem egy,
a + szimbólumok után egyenként felsoroljuk a beszúrandó sorokat,
a - szimbólumok után egyenként felsoroljuk a törlendő sorokat.
Vegyük észre, hogy az így létrehozott kimenet többsoros lesz, ahol a sorok az eredményként előállítandó lista egyes elemei lesznek. Azt feltételezhetjük, hogy a paraméterül kapott Hunk értékben a pozíciók nemnegatív értékek, az eltéréssorozat nem üres, valamint nem tartalmaz a same függvénnyel létrehozott eltéréseket. Minden más esetben állítsuk meg a kiértékelést a példákban látható hibaüzenetekkel!
A számokat szöveggé a show függvény segítségével tudjuk alakítani.
Készítsünk egy függvényt, amely kap két, akár többsoros szöveget és meghatározza az ezek közti eltéréseket a korábban említett “unified diff” formátumban!
Segítség: A paraméterként kapott szövegeket bontsuk sorokra a Prelude.lines függvény segítségével, majd ezeknek mint sorozatoknak a különbségeit állítsuk elő. Az így kiszámított különbségeket aztán bontsuk csoportokra, jelenítsük meg szövegként és fűzzük össze a Prelude.unlines alkalmazásával.