A feladat összefoglaló leírása
A feladatunk az lesz, hogy definiáljuk egy egyszerű tömörítést.
Az általunk megvalósítandó tömörítéshez kódokat fogunk meghatározni. A kódokat az előfordulási gyakoriságuk alapján fogjuk meghatározni úgy, hogy a leggyakrabban előforduló elemhez a legrövidebb, a legritkábbhoz pedig az egyik leghosszabb kód fog tartozni. Természetesen az mindig a szövegtől függ, hogy az egyes elemekhez milyen kódokat rendelünk.
A tömörítéshez szükségünk lesz egy táblára, amely tartalmazza a szöveg elemeit és a hozzájuk tartozó tömörítőkódokat. Ezt a táblát kell majd felépíteni és használni a tömörítéshez.
A tömörítőkódokat tartalmazó tábla reprezentációja a következő:
- A tábla bejegyzések sorozata (listája);
- Minden bejegyzést egy rendezett párral definiálunk, ahol a rendezett pár első eleme a szöveg valamely eleme, a második eleme pedig a hozzá tartozó tömörítőkód;
- Egy tömörítő kódot
Bittípusú elemek sorozatával definiálunk, amely értékeit aZeroésOnekonstruktorok képezik.
Például:
A tömörítéshez használt kódok előállítása egy fával szemléltethető, melyet a gyökerétől kezdünk felépíteni, majd a jobb részfát bővítjük folyamatosan addig, amíg minden elemhez nem rendeltünk egy tömörítő kódot. A tömörítéshez fontos lesz, hogy tömörítő kódok meghatározásához a szövegben az elemek előfordulási gyakoriságuk sorrendjében legyenek megadva, azaz legelől a leggyakoribb, stb.
Példa
Nézünk egy egyszerű példát és a példán keresztül a tömörítési lépéseket nagyvonalakban.
Adott az "abrakadabra" szövegünk. Elsőként az ehhez tartozó tömörítőkódokat szeretnénk előállítani, az egyes karakterek előfordulásának a gyakoriságának megállapításával.
A karakterek előfordulási gyakorisága:
'a' -> 5
'b' -> 2
'r' -> 2
'd' -> 1
'k' -> 1A nekik megfelelő tömörítőkódok:
'a' -> [Zero]
'b' -> [One, Zero]
'r' -> [One, One, Zero]
'd' -> [One, One, One, Zero]
'k' -> [One, One, One, One]Megjegyzés: A kódok az alábbi bináris fa alapján olvashatóak ki.
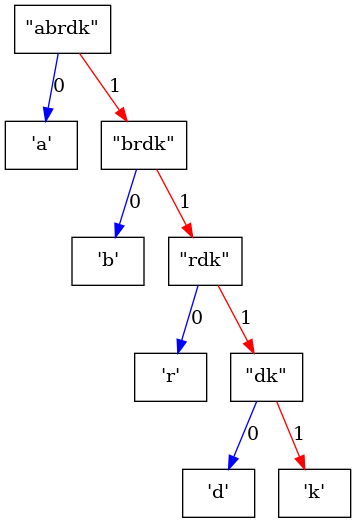
Ha vesszük a fa gyökere és a keresett karakter közötti útvonalat, az élek címkéiről leolvasható az egyes karakterekhez tartozó tömörítőkód.
Miután megállapítottuk a tömörítőkódokat a szövegben előforduló összes karakterhez, a szöveget tömöríteni tudjuk Bit értékek sorozatává.
a -> [Zero]
b -> [One, Zero]
r -> [One, One, Zero]
a -> [Zero]
k -> [One, One, One, One]
a -> [Zero]
d -> [One, One, One, Zero]
a -> [Zero]
b -> [One, Zero]
r -> [One, One, Zero]
a -> [Zero]Tehát az eredeti szövegünk tömörített változata a következő lesz.
[Zero,One,Zero,One,One,Zero,Zero,One,One,One,One,Zero,One
,One,One,Zero,Zero,One,Zero,One,One,Zero,Zero]Mivel már tömöríteni tudunk és megalkottuk a megfelelő tömörítési szótárt, ez felhasználható a kitömörítési folyamathoz.
A továbbiakban ezeket a tömörítési és kitömörítési lépéseket nézzük meg részletesebben.